


Perceptron_0.zip (1572Bytes)
The perceptron is a simple model of a neuron and was invented by Frank Rosenblatt in 1957. It has a number of external inputs, one internal input (called bias) and one output. The input values can be any number. The output of the perceptron, however, is always Boolean. When the output is '1', the perceptron is said to be activated. All of the inputs (including the bias) are weighted. Basically, the perceptron takes all of the weighted input values and adds them together. If the sum is above a threshold θ, then the perceptron is activated. Otherwise the perceptron is not and the output ƒ(x) is '0':
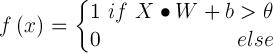
X is here the n-dimensional input vector, W the according weight vector, b the bias input and X•W the dot product.
The single-layer perceptron has one drawback: The learning algorithm does not converge if the learning set is not linearly separable. It is for instance impossible for a single-layer perceptron to learn an XOR function. This discovery end of the 1960's led to the so called AI winter. Nevertheless it can be used for many pattern recognition applications.
So far I have programmed a single-layer perceptron which has 3 inputs (one input is just an extra dimension with a constant value to replace the bias term). The sketch can be found attached. In the video the perceptron learns a NAND function with two inputs. The perceptron is also able to learn to perform a binary AND, OR or NOR function. If you try to teach it a XOR function, the algorithm will never stop though.
I have used following resources for my perceptron research:
- http://en.wikipedia.org/wiki/Perceptron
- http://www.realintelligence.net/tut_perceptron
- http://www.artificial-neural-networks.info/2008/05/perceptron-neural-network.html
I will now continue to program a more complex neural network using perceptrons and build a hardware perceptron with logic IC's and op-amps.
https://www.youtube.com/watch?v=ejWpfoAe8OU …i’ve tried simulating them before with just transistors(yup, boolean
…i’ve tried simulating them before with just transistors(yup, boolean  )…well in theory, it can simulate neural networks, but it won’t simulate psychology or thinking (i.e classical condition…e.g Pavlov’s experiments), well, Rodney Brooks’ simulation of neural nets base on his theory of subsumption architecture w/c basically makes layers and layers per se from what the robot learned/experienced, does make a hint of learning by classical or operant conditioning. i’m excited with this project, gonna be waiting for updates
)…well in theory, it can simulate neural networks, but it won’t simulate psychology or thinking (i.e classical condition…e.g Pavlov’s experiments), well, Rodney Brooks’ simulation of neural nets base on his theory of subsumption architecture w/c basically makes layers and layers per se from what the robot learned/experienced, does make a hint of learning by classical or operant conditioning. i’m excited with this project, gonna be waiting for updates 