

Old idea rekindled
This idea about very basic robot vision haunted me ever since I first saw AmandaLDR. Even before it was named after a canine. It's somewhat inspired by the evolution of the first eyes in nature: just a bunch of light sensitive cells on your rump.
Chris' ramblings about Walter the other day inspired me to make this vague idea more defined. Here are still many open questions. And I do not have the time at the moment to pursue this in my lab. So, I invite you all to give this some thought and perhaps a little experimentation. Please share!
Situation
This is set in The Carpenter's house, but it could easily be anyone's residence. Or office. Or maze. It is the imaginary "Green Room" which I think Chris has. He does not. Probably. Probably not. But the colour works for the nifty diagram.
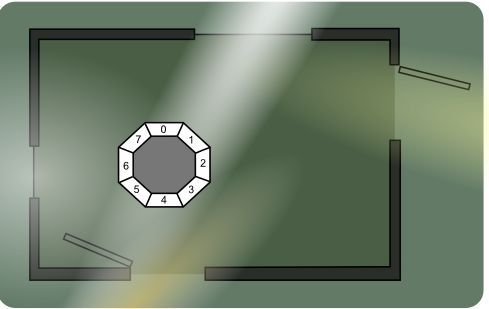
Consider a large window in the North wall, a smaller one in the West wall. In the East is a door to another room. In the South the door through which Walter just entered. He does not smell a Wumpus. That sensor is not invented yet.
Somewhere on the top of his form, Walter has eight light sensitive cells. Engineered, rather than evolved. These are humble (cheap) LDRs, somewhat encased in a light obscuring material. Each cell "looks" in a different direction. Let's number these cells 0 through 7 clockwise. (Start to count at zero if you need to prove you're a nerd. Rotate stuff clockwise to prove you're not a fundamentalist nerd.)
Each cell receives a different amount of ambient light. And thus, each LDR gives off a different voltage to each 8-bit ADC to which it is hooked up. The "brain" receives eight byte values.
Beware: Assumptions make for ugly offspring!
Assumption #1
Each room in the house has a unique lighting situation. Recognising this situation equals identifying the room.
This octagonal LDR setup will produce a data pattern based on the distribution of light around the robot. Here it is in another diagram. The cells are now rearranged in a straight line.

The top diagram reads the values in 8 bit resolution. Values range from 0 to 255 (decimal). Cell #0 reads 171 out of 255. That translates to 10101011 (binary). All eight values form a data pattern. We are now going to program some very basic pattern recognition.
Assumption #2
The eight values in such a data pattern can be combined into a memory address. Simply by stringing all the bits along into one 8x8=64 bit long word. At each such address the brain holds information about location. Or it will store some, while it is learning.
For example, the combination of all eight values above form a veeeeeery long address. This memory address holds data that has meaning to Walter along the lines of "you're in the green room facing North".
The veeeeery long, 64 bit, address is a bit of a problem. We are programming in a very stupid computer. We simply cannot juggle words that long. And also, we do not have enough memory to store even one byte in 2^64 different places. 2^64 bytes sums up to 16 Exabytes of memory. Besides, it would store the same old info in many many places anyway. That is wasteful. Of memory space and of learning time.
So we need to dumb it down a few orders of magnitude. We must make the cells "less precise" about the light levels they see. I propose to scale the values 0-255 down to 0-3. That is a factor of 64. That would save us 6 bits per cell. resulting in a total of 16 bits in the resulting pattern. That is a normal word value in a Picaxe and sums up to 2^16 = 64 KiloBytes of memory space required. That would easily fit in an EEPROM for example.
The second diagram demonstrates this low resolution data pattern being derived from the first one.
Assumption #3
An oldy: Teach your robot, rather than programming it.
Let Walter roam the house. Avoiding collisions as if it were a start here bot. Each time it enters a room it does not yet recognise (or not recognise any more), it will ask "BLEEP?". You will have to tell it somehow (suggestions welcome) where it is. Walter will store this new info into the appropriate, empty, memory nook.
Next time it enters the same room, it will hopefully receive the very same pattern through its eye. This is one reason to dumb down the patterns. A slight variation in lighting conditions (a thin tiny cloud has drifted over the house for example) will not upset the patterns too much.
Or better: the dumber patterns are not as sensitive to variations.
At first the bot would need to learn a lot. Many empty memory nooks and crannies to be filled. "Need more input, Stephanie." Just leave Walter alone in a room for 24 hours and let him soak up all the patterns it can get its eye on. Daytime and night time patterns. With and without people in the room.
He would not need to "BLEEP?" for a location, because it is under orders not to move. All patterns will register the same room as the location to recognise next time around. Walter needs to soak up each and every room. Well actually, Walter needs not be attached to this part of his brain during this educational tour around the premises. He could just be stumbling through the yard, old school style.
Assumption #4
If only I could send a part of my brain some place else to soak up interesting stuff while I were getting drunk in the yard....
Update 10 april
Oddbot and mintvelt are both suggesting the same thing. I did not mention it in the original post, because it was already too long.
They speak of smarter ways to produce a more distinctive data pattern. Ideally, each room would only produce one pattern. (That is what bar codes are all about. The pattern is then called a code.) But natural variations in light will probably cause many patterns per room.
Think of fingerprints. I could scan my right thumb a million times and the flatbed scanner would produce a million different bitmap files. Here is an imaginary example.

I could dumb it down the way I propose above. And I would end up with a much coarser bitmap. Here is the same image in a 64x64 pixel version.

This 64x64 monochrome bitmap can hold 2^4096 different combinations of pixels. That is a lot "dumber" than the above 480x480 version. But it's still not very efficient. My one thumb could still produce a zillion different patterns in an algorithm like that. Each of them different from the next by only one pixel. One of those patterns would look like this.

It's exactly the same print, but rotated 90 degrees. To a computer it holds very different data, but to us it it still the same old information: my thumb print.
Now, if I were to follow each line in the pattern and note all the crosses an junctions and endpoints, I would end up with this "roadmap".

This roadmap would hardly ever change. This map is the kind of pattern the Police are storing in their fingerprints database. Makes it much easier to search for matching patterns. Rotating it would not change the data.
In this roadmap version is a lot less data but still very distinctive information available. Compare:
Taking room prints
The same principle can be applied to the lighting situation in a room. The Green Room could be described as:
"big window, corner, doorway, dark corner, doorway, corner, small window, light corner".
I could draw up a translation table that says "big window" = 3, "dark corner" = 1, etcetera.
The pattern would then read as:
"2, 3, 1, 1, 2, 2, 2, 1".
(I bolded the first two values for recognition.)
And that is exactly what my aneurysm proposes to do. But it is still a bitmap. Rotating the bitmap would produce different data of the exact same room. The above pattern after 90 degrees of rotation would be:
"1, 1, 2, 2, 2, 1, 2, 3".
This is totally different data to a computer, but holds the same information to us. If we would turn the pattern "right side up" before feeding it into the computer, we could help it greatly in searching for matching patterns in its "room print database".
So which side is the right one? Without any external sources of orientation (like a compass), we can only go by the available data. I propose to use the brightest light source out of the eight detected levels. Either do this in hardware (put the eye on a servo) or in software (shift the values until the highesst value sits up front in the series). Both example patterns would turn into
"3, 1, 1, 2, 2, 2, 1, 2".
When you consequently use the brightest/highest value as your point of orientation, you will get consistent pattern comparisons. The hardware will probably give slightly better results because the servo can turn anywhere in high angular resolution, zooming in on the brightest light source. The software can merely rearrange the values in 22.5 degrees steps.
How about that wheather huh?
All that will hopefully account for the rotation/orientation issue. How about varying light levels? Both Oddbot and Mintvelt suggest looking at differences between values, rather than looking at absolute values. Differences themselves can be calculated absolutely or relatively.
The reasoning is like this: No matter how bright the wheather outside, the big window will always be the brightest looking wall in the room (in daytime anyway). Two suggestions:
A) bring the values down so that the lowest value is always zero. Subtract the lowest value from all values (absolute differences remain). The dark/bright relations will remain intact. Fewer different patterns, same information. Good!
B) bring the values up until the brightest value is maxed out. Multiply all values by 256 and divide by brightest value (relative differences remain).


 depending on many factors (absolute position, where the division of light is when scanning, reflection related to position, etc. etc.)
depending on many factors (absolute position, where the division of light is when scanning, reflection related to position, etc. etc.)