

Demo Movie
https://www.youtube.com/watch?v=18kzysV3wMw&feature=youtu.be
Synopsis
I have developed a variable stochastic learning automaton artificial intelligence with a REST interface that is configurable via XML, written in C# and resides in Azure. Azure gives the on demand horizontal scaling that makes this solution virtually future proofed. My successful tests include a robot teaching itself the best strategy if it runs into a wall and the AI teaching itself how to best play Pong. I may teach it to play checkers as a next step. There is still much that could be done with this but Google's Tensorflow probably would be the way to go with something like this if I was to look at it now.
The robot uses an Arduino to manage the lower level bits like motor drivers, and an ESP8266 chip manages serial communication between the Arduino and the Wifi that connects it to Azure. The ESP8266 is kind of an amperage hog especially at startup, so the robot includes its own power source of five rechargeable batteries to ensure it gets the power it needs, otherwise it doesn't work well.
I used Pong as an example since it creates a lot of data, is a simple game and I found a version in C# online that I could bend to my purposes. The video I enclosed shows it when it starts learning and then as it gets smarter until it honed its learning and won every time.
There are many applications in business, robotics, the medical arena, etc. where this could be used. I have not made the Azure service available for public consumption solely because it is a resource hog and will be expensive dollarwise to maintain in the cloud. I have published code on github though for robot, ESP8266 wifi chip and Azure REST service.
https://github.com/nhbill/CloudAI
Long Explanation
One of my interests over the past several years has been in Artificial Intelligence. The idea of being able to have a robot teach itself is something that has captivated my imagination. My initial interest was in regards to a post by MarcusB and at that time I created a robot that would teach itself what the best strategy is if it runs into something. At the time, I used some of MarcusB's code, but that code has since been replaced in the C# version for technical reasons.
https://www.robotshop.com/letsmakerobots/artificial-intelligence-framework
The algorithm I used was a Variable Stochastic Learning Automaton which was what was used originally by MarcusB. In short, if the robot has an event occur, it will randomly pick from a list of actions or strategies and assess whether the action was successful or unsuccessful. If the action was deemed successful, the probability to pick that action if the event occurs is upped. If the action was unsuccessful, the probability to pick that action again if the event occurs goes down. Over time, the best strategy will rise to the top and be called all the time. This could also be an implementation of “genetic algorithms” where the best set of reactions to an event or series of events can arise from the robot’s learning.
This was initially in C++ and I managed to just barely fit it all into an Arduino Uno. As a first implementation of the Variable Stochastic Learning Automaton, it worked. I had it bouncing around my kitchen like a super ball for the first 10 minutes or so until it taught itself the best strategy to avoid running into obstacles.
I realized from my experiment that only very simple AI could be programmed via the Arduino Uno. So, it was either move the code to a bigger embedded processor such as an Arduino Mega or come up with a distributed approach. And to move it into a bigger embedded processor was to always come up against memory or processing constraints. It really seemed that a distributed approach where some things are managed on the robot while others are managed on another larger processor with more resources seemed the best way to design a real robot that could teach itself complex functions.
The problem is where to put that line for what stays on the robot and what goes onto another computer. If communication is lost or comes and then goes, it needs to work independently. Yet, too much processing on the embedded processor will quickly overwhelm small processors. So, go with a bigger embedded processor and replicate functions on the robot and on the second computer so if communication is lost with a server it can keep going? Or, move it all to a really big processor that would sit on the robot and do all the processing on the robot? The latter means bigger battery, more expensive processor which may or may not be big enough for future needs.
To begin with, this was exactly the approach that I thought would be the best way forward. So, my code really reflects that expectation that eventually would run in some sort of embedded processor on the robot. I figured that I should do something that would operate on the robot only and not have to worry about the complexity of having to worry about whether or not the communication is lost or not.
The more I thought about it, the more I realized that a cloud based solution with its horizontal on-demand scaling was the only solution that could future proof my solution. Also, there are a lot of tools that are becoming available to help crunch data and many of these are only available in the cloud. It really seemed that a distributed in the cloud approach was the way to go. This would allow literally unlimited processing power and allow me to ask complicated questions of the data extracted from the robot. My design also needs to be decoupled as much as possible from any implementation and yet offer a great deal of flexibility in design with limited needed processing power on the robot.
The approach that I came up with was to simplify the interface down to three values entered (context string, robot id and event number) and then server responds with the action ID to respond to the event. This approach limited bandwidth and enabled the computationally and memory intensive functions to be pushed off to another computer (in this case, a server on Azure). This approach also enables the robot to potentially combine learning across multiple motivations. If the network is down for some reason, the robot is required to remember the last reaction to a particular event or event sequence, and use that to react to the event in question. This way, the robot is not completely crippled if for some reason did not receive immediate response from the server.
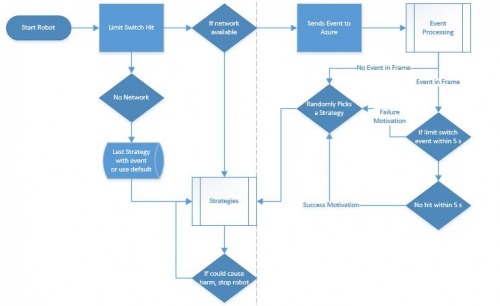
An event-based architecture also gives the opportunity to look for patterns within its experience. Each of those identified patterns becomes an event series that the AI can try to match against what is happening presently and can attempt a strategy. It then waits for a “motivating” event, ie an event that will let the AI know whether the strategy worked or not. I also have a parameter called “EventDepth” which refers to how many events the AI should try to remember.
The events that occur within the system should be handled differently by the system. To manage this complexity, I created a XML interface to the engine which manages this. These attributes of Event XML nodes tell the system how to interpret and what to do with events as they occur.
IsMotivator -- this attribute means that if this event occurs, it changes the probabilities for the first event that occurred. This has to be paired with a Motivator attribute (true or false) that describes what value is to be applied to the current strategy when this event occurs.
IsFrameBoundary -- this attribute is used to start and stop what the system perceives as a frame or which event to apply any motivation that occurs. For instance, Pong might start a frame when a user serves the ball and ends the frames when the ball is either hit by the other user or hits a wall behind a user. Otherwise, an event that occurred outside of a frame might apply a motivation event to event which it should not have been. For instance, an event may occur which seems like it should be waiting for a motivating event. But if that event occurred perhaps in the last game that ended, the motivation may be applied incorrectly. A frame that ends with an event is also the start of the next event frame.
DoesSystemRespond -- when this attribute is true, the previous event that may be waiting for a motivation, is forgotten and this becomes the event which is waiting for a motivation.
It is up to the developer to identify the most basic set of events that the robot can do and decide what properties apply to what events. Without understanding when and why to use these events, the AI will work incorrectly.
Example of Pong Game
Start Game by either player– DoesSystemRespond= true IsFrameBoundary= true IsMotivator=false
Ball Hits User Paddle- DoesSystemRespond= true IsFrameBoundary= true IsMotivator=true Motivator=false
Ball Hits AI Paddle- DoesSystemRespond= true IsFrameBoundary= true IsMotivator=true Motivator=true
Ball Goes by AI - DoesSystemRespond= true IsFrameBoundary= true IsMotivator=true Motivator=false
Ball Goes by User - DoesSystemRespond= true IsFrameBoundary= true IsMotivator=true Motivator=true
Ball hits Floor or Ceiling - - DoesSystemRespond= true IsFrameBoundary= false IsMotivator=false
A series of plays might actually be divided up into multiple frames since the end frame will become the start event for the next frame. For instance, in a Pong Game we might see
1. Start Game
2. Ball Hits AI Paddle
3. Ball Hits User Paddle
4. Ball Hits Ceiling
5. Ball Hits AI Paddle
6. Ball Hits Floor
7. Ball Hits User Wall
These events are within the AI separated into a number of frames.
Frame 1:
1. Start Game – pick a strategy to respond
2. Ball Hits AI Paddle = plus motivator for strategy
Frame 2
1. Ball Hits AI Paddle-pick a strategy to respond to event
2. Ball Hits User Paddle = minus motivator for strategy
Frame 3
1. Ball Hits User Paddle-pick a strategy to respond to event
2. Ball Hits Ceiling-pick a new strategy to respond to event pattern
3. Ball Hits AI Paddle= plus motivator for final strategy for event pattern
Frame 4
1. Ball Hits AI Paddle-pick a strategy to respond to event
2. Ball Hits Floor-pick a new strategy to respond to event pattern
3. Ball Hits User Wall = plus motivator for final strategy for event pattern
Each time there is a new frame event, the AI picks a strategy to try to respond. If the ball hits the floor or ceiling, the other strategy is thrown out and new one is tried for the event pattern (Frame 3 and 4). Based on the next motivating event, the AI then rewards the successful strategy or punishes for an unsuccessful strategy.
This falls apart though if when events happen is important. For instance, with an autonomous robot that wants to avoid running into walls, hitting the limit switch after we have gone straight for a while should have a different set of actions occur when that same limit switch is hit immediately after trying a strategy. In this instance, the second hit on a limit switch after it tries a strategy should tell us that the strategy was unsuccessful. And what happens if we try a strategy with the autonomous robot and the limit switch isn’t triggered?
My solution was to have event patterns be triggers to an event that is placed in the queue. The only way these events can occur is if a series of events occur in order. I use XML as a mechanism to configure this for the AI.
<Event Id="3" Name="LimitSwitchEventLessThan5sAfter1stEvent" IsMotivator="true" IsFrameBoundary="true" DoesSystemRespond="false" Motivator="false">
<TriggerEvents>
<TriggerEvent Id="1" Logic="Or" />
<TriggerEvent Id="2" Logic="Or" />
</TriggerEvents>
<TriggerEvents Action="ReplaceEvent">
<Time Length="5000" DoLogic="While">
<TriggerEvent Id="1" DoLogic="Or" />
<TriggerEvent Id="2" DoLogic="Or" />
</Time>
</TriggerEvents>
</Event>
The first trigger or step is if either limit switch is depressed. The second trigger is a timer that runs for 5000 milliseconds and is triggered only if either limit switch is depressed while the timer is running. The second trigger has an action of ReplaceEvent, so if either limit switch event occurs for the second trigger, it will be replaced with the event object. The event described by the XML is a motivating event, and will “punish” the strategy attempted since its Motivator attribute is false.
<Event Id="4" Name="NoLimitSwitchEventFor5sAfter1stEvent" IsMotivator="true" IsFrameBoundary="true" DoesSystemRespond="false" Motivator="true">
<TriggerEvents>
<TriggerEvent Id="1" DoLogic="Or" />
<TriggerEvent Id="2" DoLogic="Or" />
</TriggerEvents>
<TriggerEvents Action="AddToQueue">
<Time Length="5000" DoLogic="After">
</Time>
</TriggerEvents>
</Event>
</Events>
The first trigger or step is if either limit switch is depressed. The second trigger is a timer that runs for 5000 milliseconds and if no limit switch event occurs, it will add the event to the event queue after the timer is completed. The event described by the XML is a motivating event, so will “reward” the strategy attempted since its Motivator attribute is true.
<?xml version="1.0" encoding="utf-8"?>
<EventManagers>
<EventManager Session="default" Name="AutonomousRobot" Id="robot" >
<Events EventDepth="2">
<Event Id="1" Name="LeftLimitSwitch" IsMotivator="false" IsFrameBoundary="true" DoesSystemRespond="true" />
<Event Id="2" Name="RightLimitSwitch" IsMotivator="false" IsFrameBoundary="true" DoesSystemRespond="true" />
<Event Id="3" Name="LimitSwitchEventLessThan5sAfter1stEvent" IsMotivator="true" IsFrameBoundary="true" DoesSystemRespond="false" Motivator="false">
<TriggerEvents>
<TriggerEvent Id="1" Logic="Or" />
<TriggerEvent Id="2" Logic="Or" />
</TriggerEvents>
<TriggerEvents Action="ReplaceEvent">
<Time Length="5000" DoLogic="While">
<TriggerEvent Id="1" DoLogic="Or" />
<TriggerEvent Id="2" DoLogic="Or" />
</Time>
</TriggerEvents>
</Event>
<Event Id="4" Name="NoLimitSwitchEventFor5sAfter1stEvent" IsMotivator="true" IsFrameBoundary="true" DoesSystemRespond="false" Motivator="true">
<TriggerEvents>
<TriggerEvent Id="1" DoLogic="Or" />
<TriggerEvent Id="2" DoLogic="Or" />
</TriggerEvents>
<TriggerEvents Action="AddToQueue">
<Time Length="5000" DoLogic="After">
</Time>
</TriggerEvents>
</Event>
</Events>
The above snippet of XML describes all four of the events that can occur for an autonomous robot. There can be multiple sessions per robot as well as multiple robots that the AI can manage simultaneously so can possibly be learning multiple things based on events that are occurring.
<Actions ActionDepth="3">
<Action Id="1" Name="1" ClassName="ARBackupTurnRightAction" Primitive="false">
</Action>
<Action Id="2" Name="1" ClassName="ARForwardTurnLeftAction" Primitive="false">
</Action>
<Action Id="3" Name="1" ClassName="ARForwardTurnRightAction" Primitive="false">
</Action>
<Action Id="4" Name="1" ClassName="ARGoBackwardAction" Primitive="true">
<Param1Default Value="5000" Param1Offset="500" Param1Minimum="5000" Param1Maximum="10000"/>
</Action>
<Action Id="5" Name="1" ClassName="ARGoForwardAction" Primitive="true">
<Param1Default Value="5000" Param1Offset="500" Param1Minimum="5000" Param1Maximum="10000"/>
</Action>
<Action Id="6" Name="1" ClassName="ARStopAction" Primitive="true">
<Param1Default Value="5000" Param1Offset="500" Param1Minimum="5000" Param1Maximum="10000"/>
</Action>
<Action Id="7" Name="1" ClassName="ARTurnLeftAction" Primitive="true">
<Param1Default Value="5000" Param1Offset="500" Param1Minimum="5000" Param1Maximum="10000"/>
</Action>
<Action Id="8" ClassName="ARTurnRightAction" Primitive="true">
<Param1Offset Value="250" Param1Minimum="5000" Param1Maximum="10000"/>
</Action>
<Action Id="9" ClassName="ARBackupTurnLeftAction" Primitive="false">
</Action>
</Actions>
</EventManager>
These are the strategies or actions that will randomly be selected from and returned by the cloud service. Any of the actions identified with an attribute Primitive=”true” are considered to be “base” actions that can be combined into different combinations. These can then be uploaded to the controller and used as possible strategies to attempt with different parameters. The controller can refuse to accept these if it doesn’t have the memory or processing power to do so. The ActionDepth attribute on the Actions node tells us the maximum number of actions that can be put into a strategy and will limit the total number of possible actions or strategies that can be used.
Conclusion
This engine has many potential uses in robotics and in business. My next project with it will be to teach it how to play checkers.
https://www.youtube.com/watch?v=18kzysV3wMw