

Run large language model on Raspberry Pi/Jetson? How effective is it?


About AI Large Language Models
Large Language Models (LLM) are large-scale neural network models trained based on deep learning techniques, especially the Transformer architecture. They learn the structure and regularity of language by processing and analyzing large amounts of text data, thereby generating, understanding, and translating human language. These models typically have hundreds of millions to hundreds of billions of parameters, enabling them to perform well in a wide range of natural language processing (NLP) tasks, such as language generation, dialogue understanding, text summarization, translation, etc.
In this era of technological development, large language models are changing our lives.
Whether it is content creation or scientific research, large language models are used in various fields.
Today we are going to show that how to run some different large language models on Raspberry Pi and Jetson development boards.
What kind of results can we get by running different AI big language models on different embedded development boards?
How to deploy AI large language models on Jetson or Raspberry Pi?
The operation video is as follows.
1. What is Ollama?
The key to deploying large language models on embedded controllers such as Raspberry Pi or Jetson is a powerful open source tool---Ollama.
Official website: https://ollama.com/
GitHub: https://github.com/ollama/ollama
Ollama is designed to simplify the deployment process of large language models, eliminating the tediousness of configuring from scratch. With just a few lines of commands, you can easily deploy and run the model.
After many tests, many large language models can perform well and run smoothly with the support of Ollama.
2. Deployment environment
You need to prepare a development board (RAM: 4GB or more) and a SD (TF) card (16G or more).
Raspberry Pi 5B (8G RAM): Run 8B and below parameter models Raspberry Pi 5B (4G RAM): Run 3B and below parameter models.
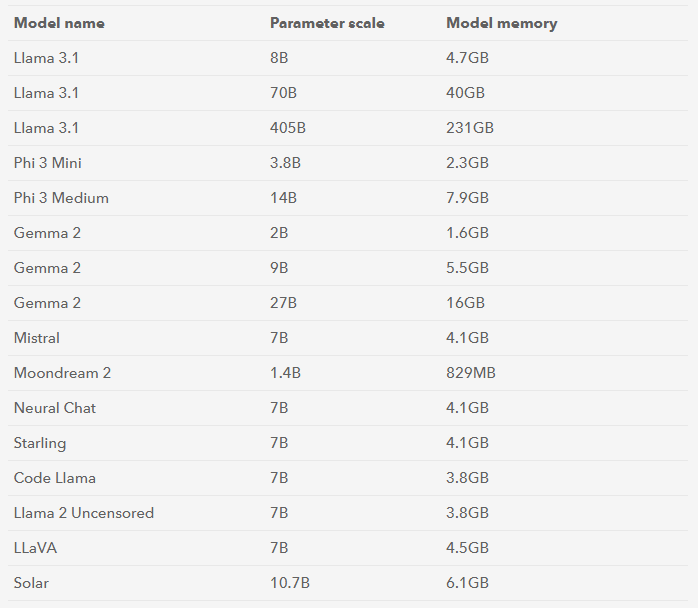
In addition, we also need to prepare a system disk storage medium of more than 16GB to download more models.
3.Ollama installation
The first step is to turn on the computer, open the Raspberry Pi or Jetson terminal, and enter the following command:

When the system displays the content shown above, it means that the installation is successful.
If you are using Raspberry Pi deployment, there will be a warning that no NVIDIA/AMD GPU is detected and Ollama will run in CPU mode. We can ignore this warning and proceed to the next step.
If you are using a device such as Jetson, there is no such warning. Using NVIDIA can have a GPU bonus and get a smoother experience.
4.Use of Ollama
Enter the command ollama in the terminal and you will see the prompt as shown below:
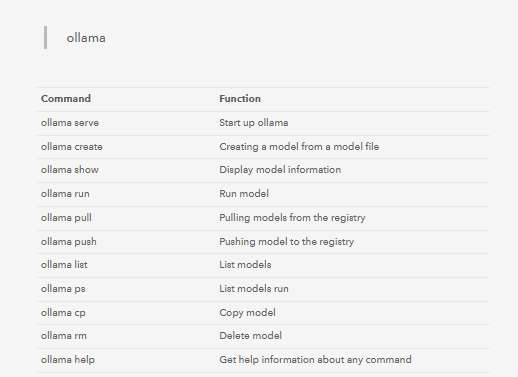
These are all instructions related to model operation. Later, we can enter instructions in the terminal to pull the model from the registry.
When the following prompt appears, it means that the model has been downloaded and we can interact with the text.
Run the AI large language model on the Jetson development board.
This time we use Jetson Orin NX 16GB and 8GB versions as the test platform. With its built-in GPU, Jetson Orin NX shows excellent performance in processing large-scale data sets and complex algorithms, and can respond to most model requests within 2 seconds, far exceeding other edge devices.
In the test, the model with a scale of 7 billion parameters performed best on Jetson Orin NX. Although the processing speed is slightly slower than the smaller model, the response accuracy is higher. In addition, LLaVA also shows good performance in processing multimodal content of pictures and texts.
The test video is as follows:
Specific conditions and results of several models with good running effects.
1.WizardLM2 [Microsoft artificial intelligence large language model]
Parameter amount: 7B
Context length: 128K
16G processing speed: 13.1 token/s
8G processing speed: 6.4 token/s
User experience rating: ★★★★
Advantages: Faster response speed
Disadvantages: average response accuracy
2.Phi-3 [Microsoft small language model]
Parameter amount: 3.8B
Context length: 128K
16G processing speed: 18.5 token/s
8G processing speed: 17.5 token/s
User experience rating: ★★★★
Advantages: higher response accuracy, richer content
Disadvantages: slower response speed
3.LlaVA [Meta AI open source large language model series]
Used version parameter amount: 8B
Context length: 8K
16G processing speed: 13.5 token/s
8G processing speed: 3.7 token/s
User experience rating: ★★★★
Advantages: Better reply accuracy, can reply with pictures
Disadvantages: Bad Chinese conversation ability
4.Gemma [Lightweight open language model developed by Google]
Parameters: 7B
Context length: 4K
16G processing speed: 10.2 token/s
8G processing speed: 4.2 token/s
User experience rating: ★★★★
Advantages: Better reply accuracy, better user experience
5.LLaVA [Multimodal large model, integrating visual recognition technology and language model]
Parameters: 7B
Context length: 4K
16G processing speed: 13.5 token/s
8G processing speed: 3.7 token/s
User experience rating: ★★★★
Advantages: Better reply accuracy, can reply with pictures
Disadvantages: average reply speed
6.Qwen2 [Large language model open sourced by Alibaba Cloud team]
Parameters: 7B
Context length: 128K
16G processing speed: 10.2 token/s
8G processing speed: 4.2 token/s
User experience rating: ★★★★★
Advantages: Good Chinese context experience, better reply accuracy
Running AI large language model on the Raspberry Pi development board.
This test uses the Raspberry Pi 5-8G version as the test platform.
Using the Raspberry Pi 5-4GB version, many models cannot run on this motherboard due to the small memory. So we selected some large language models with better running effects, and the test results are as follows.
1.WizardLM2 [Microsoft large language model of artificial intelligence]
Parameter volume: 7B
Context length: 128K
Response speed: 30 seconds
User experience rating: ★★★
Advantages: correct and intelligent content
Disadvantages: slower response speed
2.Phi-3 [Microsoft small language model]
Parameter volume: 3.8B
Context length: 4K
Response speed: 5 seconds
User experience rating: ★★★
Advantages: Faster response
Disadvantages: Bad accuracy, sometimes random replies
3.Llama [Meta AI open source large language model series]
Used version parameter volume: 8B
Context length: 8K
Response speed: 10 seconds
User experience rating: ★★★★
Advantages: Good performance
Disadvantages: Bad Chinese conversation ability
4.Gemma [Lightweight open language model developed by Google]
Parameters: 2B
Context length: 1K
Response speed: 6-7 seconds
User experience rating: ★★★★
Advantages: concise responses and good user experience.
Disadvantages: speed and accuracy depend on model size.
5.Gemma [Lightweight open language model developed by Google]
Parameters: 7B
Context length: 4K
Response speed: 20 seconds
User experience rating: ★★★★
Advantages: concise replies, good user experience
Disadvantages: speed and accuracy depend on model size
6.LLaVA [Multimodal large model, integrating visual recognition technology and language model]
Parameters: 7.24B
Context length: 2K
Response speed: 10 seconds
User experience rating: ★★★★★
Advantages: can process image and text information, better accuracy
7.Qwen2 [Large language model open sourced by Alibaba Cloud team]
Parameters: 7B
Context length: 128K
Response speed: 10 seconds
User experience rating: ★★★★★
Advantages: supports multiple advanced functions, good Chinese context experience
According to the test results, we know that
WizardLM2 responds accurately but slowly;
Phi-3 responds quickly due to its smaller model size, but with lower accuracy;
Llama is slightly insufficient in handling Chinese conversations;
Gemma provides a good balance between speed and accuracy;
LLaVA has won praise for its multimodal processing capabilities;
Qwen2 performs best in Chinese context experience.
After our actual tests, large language models can indeed run on edge computing devices with limited performance, especially in scenarios with limited network or privacy protection requirements. However, the use of offline large language models is not as smooth as cloud conversations. Secondly, the running effect of the 7 billion model is much slower than that of the 3.8 billion and 2 billion models, but the reply accuracy is better than them.
However, as time goes by, the application scenarios of large language models will definitely become more and more mature, and even multimodal large models combining vision and audio will become more and more. We will see more edge solutions being deployed on edge devices such as Raspberry Pi/Jetson.
Thanks for helping to keep our community civil!
This post is an advertisement, or vandalism. It is not useful or relevant to the current topic.
You flagged this as spam. Undo flag.Flag Post
Your post is currently under review by our moderation team. The review process usually takes up to 48 business hours.
You can track your post's status in the "My Content" section of your profile. Once approved, it will be published and visible to others.

Thank you for contributing to our community!